Can you calculate a vector database by hand?
AI by Hand - Tom Yeh
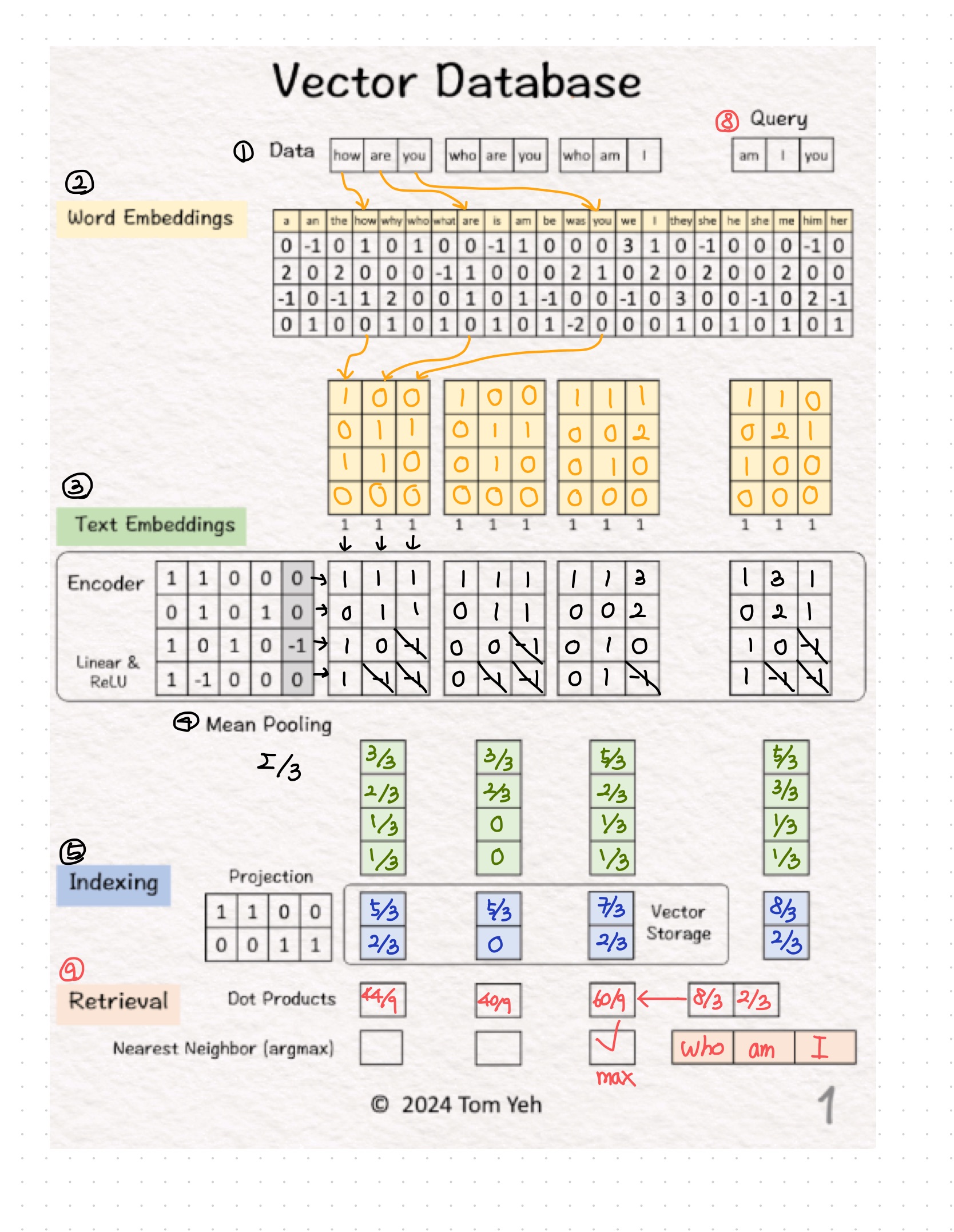
Vector Database
14. Can you calculate a vector database by hand? - Tom Yeh


CLS Pooling
CLS Pooling uses the final hidden state of a “CLS” token added at the beginning of the sentence to obtain a vector that represents the sentence.
CLS 풀링은 트랜스포머 기반 모델에서 주로 사용되는 기법 중 하나입니다. 트랜스포머 모델에서는 각 입력에 대해 여러 토큰이 존재하고, 각 토큰은 모델을 통과하며 벡터로 표현됩니다. 여기서 중요한 것은, 문장을 대표하는 벡터를 얻기 위해 문장의 시작 부분에 특별한 토큰인 “CLS” (classification) 토큰을 추가한다는 점입니다.
문장 처리 과정에서 모델의 입력으로 들어간 “CLS” 토큰은 모델의 여러 층을 거치면서 정보를 축적하고 갱신됩니다. 모델의 마지막 층에서 “CLS” 토큰에 해당하는 벡터는 해당 문장의 정보를 종합적으로 내포하게 되는데, 이 벡터를 사용하여 문장 전체를 대표하는 벡터로 활용합니다. 이렇게 얻은 벡터는 문장의 의미를 간략하게 요약하며, 이를 기반으로 문장 분류, 감정 분석 등의 다양한 자연어 처리 작업에 사용될 수 있습니다.
간단히 말해, CLS 풀링은 문장의 맥락을 포괄하는 벡터를 생성하기 위해 “CLS” 토큰의 최종 상태를 활용하는 것입니다. 이 방법은 전체 문장에 걸쳐 얻은 정보를 하나의 벡터로 요약할 수 있게 해주어, 효율적으로 문장 또는 텍스트 데이터를 처리할 수 있도록 돕습니다.
ANN (Approximate Nearest Neighbor)
Approximate Nearest Neighbor (ANN) is a method for quickly finding similar items in large datasets while reducing computational costs.
근사 최근접 이웃(ANN, Approximate Nearest Neighbor)은 데이터 포인트 사이의 유사도를 빠르게 계산하여 가장 가까운 이웃을 찾는 알고리즘입니다. 이 알고리즘은 최근접 이웃 검색보다 덜 정확하지만 더 빠른 결과를 제공하는 것을 목표로 합니다.
여기서 “근사”라는 용어는 완벽하게 가장 가까운 이웃을 찾는 것이 아니라, 충분히 유사하고 계산 비용이 적은 방법을 통해 이웃을 찾는다는 의미입니다. 이를 통해 대량의 데이터를 다룰 때 시간과 자원을 절약할 수 있습니다.
ANN의 동작 방식은 크게 세 단계로 나눌 수 있습니다:
-
인덱싱(Indexing): 데이터 포인트를 미리 정리하는 단계입니다. 이 과정에서 데이터는 공간을 효율적으로 나누거나 계층적으로 구성하여 저장됩니다. 이렇게 하면 검색 시 필요한 데이터 포인트만 빠르게 찾아볼 수 있습니다.
-
검색(Searching): 쿼리(찾고자 하는 데이터 포인트)가 주어지면, ANN 알고리즘은 저장된 데이터 중에서 쿼리와 가장 유사한 데이터 포인트를 찾습니다. 이 과정은 인덱스를 활용하여 불필요한 비교를 최소화하면서 진행됩니다.
-
결과 반환(Returning Results): 검색 과정에서 찾아낸 유사한 데이터 포인트들을 순서대로 나열하여 결과로 반환합니다. 이 때, 가장 유사도가 높은 데이터 포인트가 최근접 이웃으로 선택됩니다.
이러한 과정을 통해, ANN은 대규모 데이터셋에서도 빠르게 유사한 이웃을 찾을 수 있으며, 데이터 과학, 이미지 검색, 추천 시스템 등 다양한 분야에서 활용됩니다.
HNSW (Hierarchical Navigable Small Worlds)
Hierarchical Navigable Small Worlds (HNSW) is an algorithm that enables fast and accurate nearest neighbor searches using a multi-layer structure.
HNSW(Hierarchical Navigable Small Worlds) 알고리즘은 계층적인 구조를 통해 빠르고 정확한 최근접 이웃 검색을 가능하게 하는 방법입니다. 이 알고리즘은 효율적인 탐색을 위해 “소규모 세계” 현상을 이용하는데, 이는 각 노드가 몇 개의 가까운 노드(이웃)에만 연결되어 있음에도 불구하고 전체 네트워크를 빠르게 탐색할 수 있게 해줍니다. HNSW는 이 구조를 다중 계층으로 확장하여 검색 효율을 크게 향상시킵니다.
HNSW의 작동 원리는 다음과 같습니다:
-
계층적 구조: HNSW는 데이터 포인트를 여러 계층(레벨)에 걸쳐 구성합니다. 최상위 레벨은 전체 데이터의 근사적인 뷰를 제공하고, 계층이 낮아질수록 더 정밀한 뷰를 제공합니다. 이 계층적 구조는 맨 위 레벨에서 검색을 시작하여 점차 하위 레벨로 내려가면서 진행되므로, 검색 경로가 최적화됩니다.
-
효율적인 네비게이션: 각 계층에서, 데이터 포인트는 소수의 가장 가까운 이웃들과만 연결됩니다. 이 연결들은 데이터 포인트 간의 지역적인 구조를 반영하므로, 쿼리 포인트가 주어졌을 때 시작점에서부터 연결을 따라 빠르게 목표 지점(최근접 이웃)까지 도달할 수 있습니다.
-
동적 추가 및 삭제: HNSW는 데이터 포인트를 동적으로 추가하거나 삭제할 수 있어서, 변화하는 데이터셋에도 효과적으로 대응할 수 있습니다. 이는 실시간 데이터 처리나 온라인 학습 시나리오에서 특히 유용합니다.
-
빠른 검색 속도: 계층적 구조와 효율적인 네비게이션 덕분에, HNSW는 전체 데이터셋을 선형적으로 검색하는 것보다 훨씬 빠른 검색 속도를 제공합니다. 이는 대규모 데이터셋에서도 높은 성능을 유지할 수 있게 해줍니다.
결론적으로, HNSW는 계층적 구조와 효율적인 네비게이션 전략을 통해 빠르고 정확한 최근접 이웃 검색을 실현합니다. 이는 대규모 데이터베이스와 실시간 시스템에서의 응용에 매우 적합합니다.