DEVOCEAN OpenLab 스터디 - Query Expansion, AutoRAG
AI 중심의 오픈 스터디
안녕하세요, OpenLab LLMOps 프로젝트에서 스터디에 참여하고 있는 김하림입니다.
저는 이번에 AutoRAG에서의 쿼리 확장(Query Expansion) 기법에 대해 소개하고자 합니다. 이 글은 쿼리 확장의 정의와 장점, 그리고 주요 파라미터에 대해 다루고 있습니다. 검색 엔진이나 정보 검색 시스템에서 쿼리 확장은 매우 중요한 역할을 합니다. 이를 통해 검색 결과의 관련성을 높이고, 더 나은 데이터를 제공할 수 있습니다.
이 블로그 포스트에서는 쿼리 확장의 기본 개념부터 구체적인 파라미터 설정까지 자세히 설명하고 있으니, AutoRAG를 처음 접하시는 분들도 쉽게 이해할 수 있을 것입니다. 먼저, AutoRAG가 무엇인지 간단하게 소개드리고 바로 Query Expansion에 대해 설명해보겠습니다.
AutoRAG
🤷♂️ 왜 AutoRAG인가?
수많은 RAG 파이프라인과 모듈들이 존재하지만, “자신의 데이터”와 “자신의 사용 사례”에 적합한 파이프라인이 무엇인지 알기란 쉽지 않습니다. 모든 RAG 모듈을 만들고 평가하는 것은 매우 시간이 많이 걸리고 어렵습니다. 그러나 이렇게 하지 않으면 나에게 가장 적합한 RAG 파이프라인을 찾을 수 없습니다.
바로 이 점에서 AutoRAG가 필요합니다.
🤸♂️ AutoRAG가 어떻게 도울 수 있을까요?
AutoRAG는 “자신의 데이터”에 최적화된 RAG 파이프라인을 찾는 도구입니다. 이를 통해 다양한 RAG 모듈을 자동으로 평가하고, 자신의 사용 사례에 가장 적합한 RAG 파이프라인을 찾을 수 있습니다.
AutoRAG는 다음과 같은 기능을 지원합니다:
- 데이터 생성: 자신의 문서를 사용하여 RAG 평가 데이터를 생성합니다.
- 최적화: 자신의 데이터에 최적화된 최고의 RAG 파이프라인을 찾기 위해 실험을 자동으로 수행합니다.
- 배포: 단일 YAML 파일로 최적의 RAG 파이프라인을 배포합니다. 또한 FastAPI 서버를 지원합니다.
AutoRAG를 통해, 더 이상 복잡한 RAG 파이프라인 선택에 고민할 필요 없이 자신의 데이터와 사용 사례에 딱 맞는 솔루션을 쉽게 찾고 배포할 수 있습니다.
Query Expansion
스터디 문서: 1. Query Expansion
🔎 정의
검색 할 때, 사용자의 쿼리를 재구성하거나 추가하여 쿼리와 검색 결과 간의 간극을 최소화하는 과정을 의미합니다. 쿼리를 검색에 바로 사용하지 않고 쿼리를 확장하여 검색 결과의 관련성을 높이기 위해 쿼리를 변형합니다.
🤸 장점
- 다양한 유형의 질의에 더 잘 대응할 수 있게 됩니다.
- 이전보다 더욱 관련성 높은 데이터를 검색할 수 있게 되어 생성된 출력의 정확성을 향상시킬 수 있게 됩니다.
🔢 파라미터
Strategy
성능 평가: query expansion을 수행한 결과 자체를 객관적으로 평가하는 것은 어렵습니다. 따라서, 쿼리를 사용해 검색을 실행한 후 그 결과를 평가합니다. 이 과정에서 필요한 검색 및 평가 파라미터를 strategy에 설정합니다.
Tip: 자세한 사항은 검색 노드의 파라미터를 참고하세요.
Strategy Parameters:
평가 지표 (Metrics): retrieval_f1, retrieval_recall, retrieval_precision 등의 지표를 사용하여 쿼리 확장이 검색 결과에 미치는 영향을 평가합니다.
속도 기준 (Speed Threshold): speed_threshold는 모든 노드에 적용됩니다. 이 threshold는 쿼리를 처리하는 데 걸리는 평균 시간보다 오래 걸리는 방법은 사용하지 않도록 하는 것입니다. 쉽게 말해, 쿼리를 처리하는 데 너무 오래 걸리는 방법을 배제하여 더 빠른 방법들만 사용하도록 합니다. 구현 방법이 궁금하여 코드를 확인해보았습니다.
- 함수 실행 시간 측정:
measure_speed함수는 주어진 함수func의 실행 시간을 측정하여 초 단위로 반환합니다.
# strategy.py def measure_speed(func, *args, **kwargs): """ Method for measuring execution speed of the function. """ start_time = time.time() result = func(*args, **kwargs) end_time = time.time() return result, end_time - start_time - 모듈 실행 및 시간 측정:
- 각 모듈의 실행 시간과 결과를 측정하여
results와execution_times에 저장합니다. - 각 모듈의 평균 실행 시간을 계산합니다.
# run.py: run query expansion results, execution_times = zip(*map(lambda task: measure_speed( task[0], project_dir=project_dir, previous_result=previous_result, **task[1]), zip(modules, module_params))) average_times = list(map(lambda x: x / len(results[0]), execution_times)) - 각 모듈의 실행 시간과 결과를 측정하여
- speed_threshold로 필터링:
- speed_threshold가 설정되어 있는지 확인합니다.
filter_by_threshold함수를 사용하여 평균 실행 시간이speed_threshold를 초과하는 모듈을 필터링합니다. 이 함수는average_times리스트와 비교하여speed_threshold를 초과하는 모듈들을 결과에서 제거합니다.
# run.py if general_strategy.get('speed_threshold') is not None: results, filenames = filter_by_threshold(results, average_times, general_strategy['speed_threshold'], filenames)speed_threshold필터링 과정은 설정된 임계값을 초과하는 실행 시간을 가진 모듈들을 제거하여, 더 빠르게 실행되는 모듈들만 결과에 포함시키는 방식인 것을 알 수 있었습니다.
Top_k: Top_k는 검색 결과에서 상위 몇 개의 결과를 고려할지를 결정하는 파라미터입니다. 예를 들어, Top_k가 10으로 설정되어 있다면, 검색된 결과 중 상위 10개의 결과만 평가에 사용됩니다.
검색 모듈 (Retrieval Modules): query expansion node는 검색 노드의 모든 모듈과 모듈 파라미터를 사용할 수 있습니다.
- bm25: 검색을 위한 가장 인기 있는 TF-IDF 방법으로, 단어가 문서에서 얼마나 중요한지를 반영합니다., 희소 검색이라고도 불리는 BM25는 단어의 빈도를 사용합니다. 특정 도메인의 문서를 사용할 경우 BM25가 VectorDB보다 더 유용할 수 있습니다. BM25는 BM25Okapi 알고리즘을 사용해 구절을 스코어링하고 순위를 매깁니다.
- porter_stemmer: 기본 토크나이즈 방법으로 영어에 최적화되어 있습니다. 문장을 단어로 나누고, 어간을 추출합니다. 예를 들어, ‘studying’과 ‘studies’를 ‘study’로 바꿉니다.
- ko_kiwi: 한국어 문서를 위한 kiwi 토크나이저를 사용합니다. 한국어 문서에는 이를 사용하는 것을 강력히 추천합니다 🤩 자세한 내용은 이 곳에서 확인할 수 있습니다.
- space: 단순히 단어를 공백으로 나누는 방법입니다. 간단하지만 다국어 문서에 유용할 수 있습니다.
- Huggingface AutoTokenizer: huggingface에서 제공하는 모든 AutoTokenizer를 사용할 수 있습니다.

-
vectordb: VectorDB 모듈은 VectorDB를 백엔드로 사용하는 검색 모듈입니다. 이 클래스를 사용하면 밀집 검색(Dense Retrieval)을 쉽게 수행할 수 있습니다.


- hybrid_rrf: target_modules 및 rrf_k 파라미터와 함께 사용
- hybrid_cc: target_modules 및 weights 파라미터와 함께 사용
config.yaml file 예시
node_lines: - node_line_name: pre_retrieve_node_line # Arbitrary node line name nodes: - node_type: query_expansion strategy: metrics: [retrieval_f1, retrieval_recall, retrieval_precision] speed_threshold: 10 top_k: 10 retrieval_modules: - module_type: bm25 - module_type: vectordb embedding_model: openai modules: - module_type: pass_query_expansion - module_type: query_decompose llm: openai temperature: [0.2, 1.0] - module_type: hyde llm: openai max_token: 64
📦 모듈
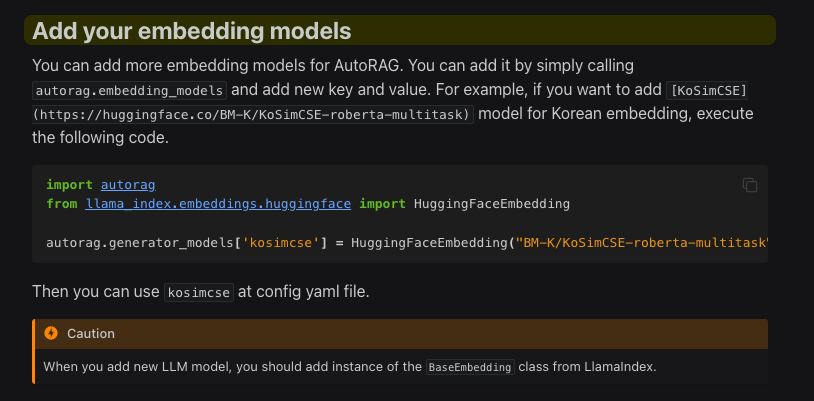
pass_query_expansion
pass_query_expansion 모듈의 목적은 query expansion 모듈을 사용하지 않을 때의 성능을 테스트하는 것입니다. 상황에 따라 query expansion node를 사용하지 않는 것이 더 나은 선택이 될 수 있습니다. 이 모듈을 통해 쿼리 확장없이도 검색 성능을 자동으로 평가할 수 있습니다.
query_decompose
사용자가 질문을 할 때, 그 질문이 단일 질의로 명확하게 답변되지 않을 수 있습니다. 어떤 경우에는 질문을 여러 하위 질문으로 나누고, 각각의 하위 질문에 대한 답변을 모은 후, 이를 종합하여 답변을 제공해야 합니다.
예를 들어, 사용자가 “LangChain과 LlamaIndex 어떻게 다른가요?”라고 물었을 때, LangChain과 LlamaIndex를 각각 설명하는 문서는 있지만, 둘을 비교하는 문서는 없을 수 있습니다. 이럴 때는 “LangChain은 무엇인가요?”와 “LlamaIndex는 무엇인가요?”라는 하위 질문을 만들어 각각의 답변을 얻은 후 이를 결합하는 것이 더 나은 결과를 제공할 수 있습니다.
이렇게 질문을 여러 개의 하위 질문으로 나누는 과정을 ‘질의 분해(query decomposition)’라고 합니다. 때로는 ‘하위 질의 생성(sub-query generation)’이라고도 부릅니다.
프롬프트
query_decompose는 LLM 모델을 사용하여 multi-hop question’을 ‘multiple single-hop questions’으로 분해하는 모듈입니다. 이 모듈은 Visconde: Multi-document QA with GPT-3 and Neural Reranking 논문에서 사용하는 기본적인 decomposition prompt를 사용한다고 합니다.
# query_decompose.py
decompose_prompt = """Decompose a question in self-contained sub-questions. Use \"The question needs no decomposition\" when no decomposition is needed.
Example 1:
Question: Is Hamlet more common on IMDB than Comedy of Errors?
Decompositions:
1: How many listings of Hamlet are there on IMDB?
2: How many listing of Comedy of Errors is there on IMDB?
Example 2:
Question: Are birds important to badminton?
Decompositions:
The question needs no decomposition
Example 3:
Question: Is it legal for a licensed child driving Mercedes-Benz to be employed in US?
Decompositions:
1: What is the minimum driving age in the US?
2: What is the minimum age for someone to be employed in the US?
Example 4:
Question: Are all cucumbers the same texture?
Decompositions:
The question needs no decomposition
Example 5:
Question: Hydrogen's atomic number squared exceeds number of Spice Girls?
Decompositions:
1: What is the atomic number of hydrogen?
2: How many Spice Girls are there?
Example 6:
Question: {question}
Decompositions:"
"""
- 질문을 자체적으로 완전한 서브 질문으로 분해할 것을 지시합니다.
- 분해가 필요 없는 경우 “The question needs no decomposition”을 사용하라고 명시합니다.
- 분해가 필요한 질문과 분해가 필요 없는 질문의 예시를 적절하게 제공하고 있습니다.
예시 config.yaml
modules:
- module_type: query_decompose
llm: openai
temperature: [0.2, 1.0] # temperature가 0.2일 때, 1.0일 때의 성능을 비교
- 모듈 파라미터
- llm: 쿼리 분해를 수행할 llm을 지정합니다. 쿼리 확장 노드는 사용되는 대형 언어 모델(LLM)과 관련된 파라미터를 설정해야 합니다. 기본적으로 openai만 입력하고 특정한 모델을 지정하지 않은 경우, llama_index에 설정된 기본 모델인 gpt-3.5-turbo를 사용하게 됩니다.
Tip: 사용할 수 있는 LLM 모델을 확인하고 싶다면 이 문서를 확인해보세요.
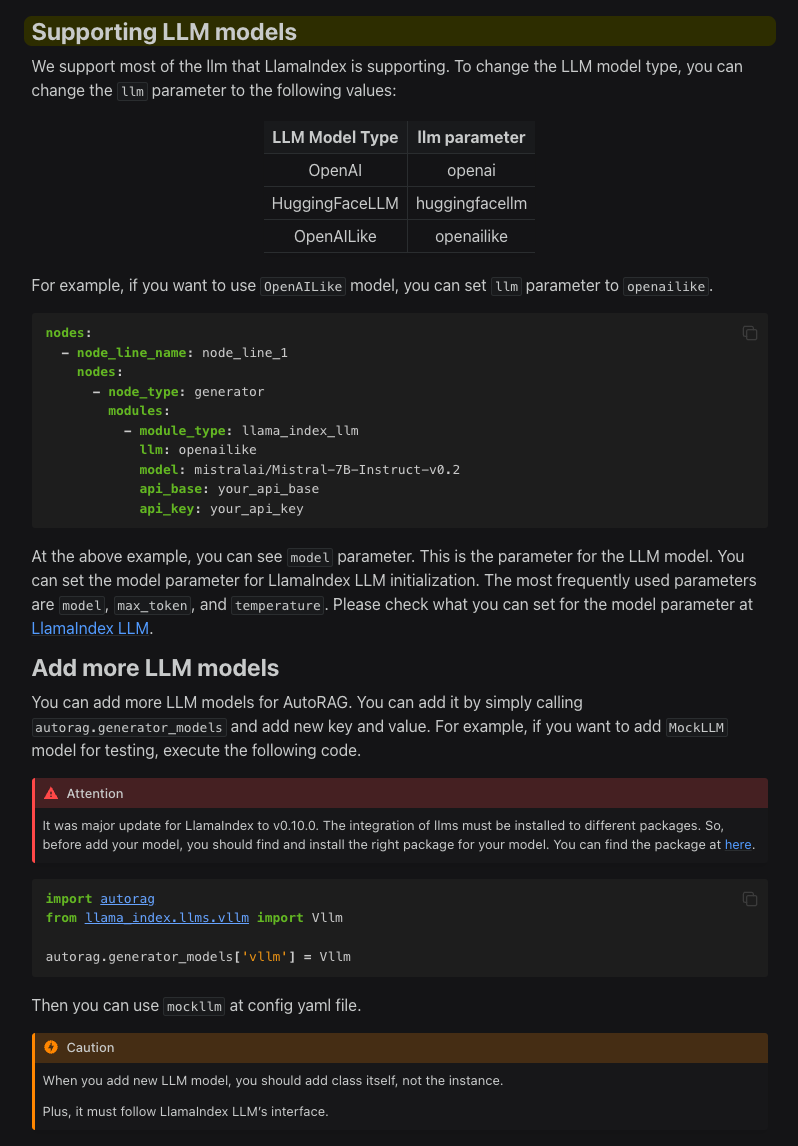
- 추가 파라미터
-
batch: 한 번에 수행할 LLM 호출 수를 설정합니다. 기본값은 16입니다.

-
model, temperature, max_token과 같은 기타 LLM 관련 파라미터를 설정할 수 있습니다. 이러한 파라미터는 키워드 인수(kwargs)로 LLM에 전달되어 LLM의 동작을 다양하게 커스텀할 수 있습니다. 이 파라미터들은 LlamaIndex 문서에서 확인할 수 있습니다.
-
hyde
HyDE는 “Hypothetical Document Embedding”의 약어로, 대형 언어 모델(LLM)을 사용하여 주어진 쿼리에 대해 가상의 문서를 생성하는 방법을 의미합니다. 이 방식은 Precise Zero-shot Dense Retrieval without Relevance Labels 논문에서 제안된 개념을 바탕으로 하고 있습니다.
# hyde.py
hyde_prompt = "Please write a passage to answer the question"
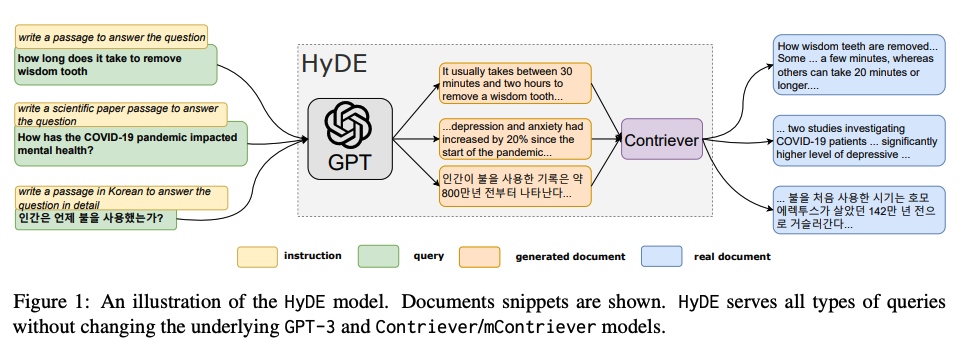
- 쿼리 입력:
- “사랑니를 빼는 데 얼마나 걸리나요?”와 같은 일반적인 질문
- “COVID-19 팬데믹이 정신 건강에 어떤 영향을 미쳤나요?”와 같은 과학적인 논문 관련 질문
- “인간은 언제부터 불을 사용했는가?”와 같은 상세한 질문
- GPT-3를 통한 가상 문서 생성:
- “사랑니를 제거하는 데는 보통 30분에서 2시간 정도 걸립니다.”
- “팬데믹 시작 이후 우울증과 불안감이 20% 증가했습니다.”
- “인간이 불을 사용한 기록은 약 80만 년 전부터 나타납니다.”
- Contriever를 통한 문서 검색:
- Contriever 모델은 가상의 문서와 유사한 실제 문서를 검색하여 관련 정보를 제공합니다.
- “사랑니가 제거되는 방법은… 몇 분에서 20분 이상 걸릴 수 있습니다.”
- “COVID-19 환자를 조사한 두 연구에서… 우울증의 높은 비율을 발견했습니다.”
- “불을 처음 사용한 시기는 호모 에렉투스가 약 142만 년 전에 시작한 것으로 보입니다.”
- Contriever 모델은 가상의 문서와 유사한 실제 문서를 검색하여 관련 정보를 제공합니다.
예시 config.yaml
modules:
- module_type: hyde
llm: openai
max_token: 64
- 모듈 파라미터
- llm: 쿼리 분해를 수행할 llm을 지정합니다. 쿼리 확장 노드는 사용되는 대형 언어 모델(LLM)과 관련된 파라미터를 설정해야 합니다. 기본적으로 openai만 입력하고 특정한 모델을 지정하지 않은 경우, llama_index에 설정된 기본 모델인 gpt-3.5-turbo를 사용하게 됩니다.
Tip: 사용할 수 있는 LLM 모델을 확인하고 싶다면 이 문서를 확인해보세요.
- 추가 파라미터
- batch: 한 번에 수행할 LLM 호출 수를 설정합니다. 기본값은 16입니다.
- model, temperature, max_token과 같은 기타 LLM 관련 파라미터를 설정할 수 있습니다. 이러한 파라미터는 키워드 인수(kwargs)로 LLM에 전달되어 LLM의 동작을 다양하게 커스텀할 수 있습니다. 이 파라미터들은 LlamaIndex 문서에서 확인할 수 있습니다.