Aggregation of Reasoning Framework
A Hierarchical Framework for Enhancing Answer Selection in LLM
🧠 Aggregation of Reasoning
🎯 배경
일반적인 프롬프트 접근 방식 중 하나는 여러 추론을 샘플링한 후 가장 자주 등장하는 답을 최종 예측으로 선택하는 것입니다. 이는 흔히 Self-Consistency 방법으로 알려져 있습니다. 하지만 이 접근 방식은 정답이 적게 나오는 경우에는 실패할 수 있다는 단점이 있습니다. 이러한 문제를 해결하기 위해 AoR 접근 방식이 도입되었습니다.
최종 답변 선택을 개선하기 위해, LLM의 추론 과정을 평가하는 능력을 활용한 계층적 추론 집합 프레임워크인 AoR(Aggregation of Reasoning)을 소개합니다. AoR은 LLM의 문맥 창 제한으로 인해 모든 추론 체인을 동시에 평가할 수 없는 문제를 해결합니다. 먼저 각 추론 체인을 그들의 답변에 따라 집계한 후, 두 단계의 평가 과정을 거칩니다.
첫 번째 단계는 로컬 점수 매기기(local-scoring)로, 동일한 답변을 도출하는 체인들을 평가합니다. 이 단계에서는 답변의 일관성을 기반으로 추론 과정의 타당성과 추론 단계의 적절성을 중점적으로 평가합니다.
두 번째 단계는 글로벌 평가(global-evaluation)로, 서로 다른 답변 그룹에서 논리적으로 가장 일관되고 방법론적으로 가장 타당한 체인들을 평가합니다. 목표는 추론 과정과 해당 답변 간의 일관성과 일치성을 가장 잘 나타내는 추론 체인을 식별하여 이를 최종 출력으로 지정하는 것입니다.
🤔 AoR 프레임워크란 무엇인가요?
AoR 접근 방식은 Local-Scoring과 Global-Evaluation의 두 단계로 구성됩니다.
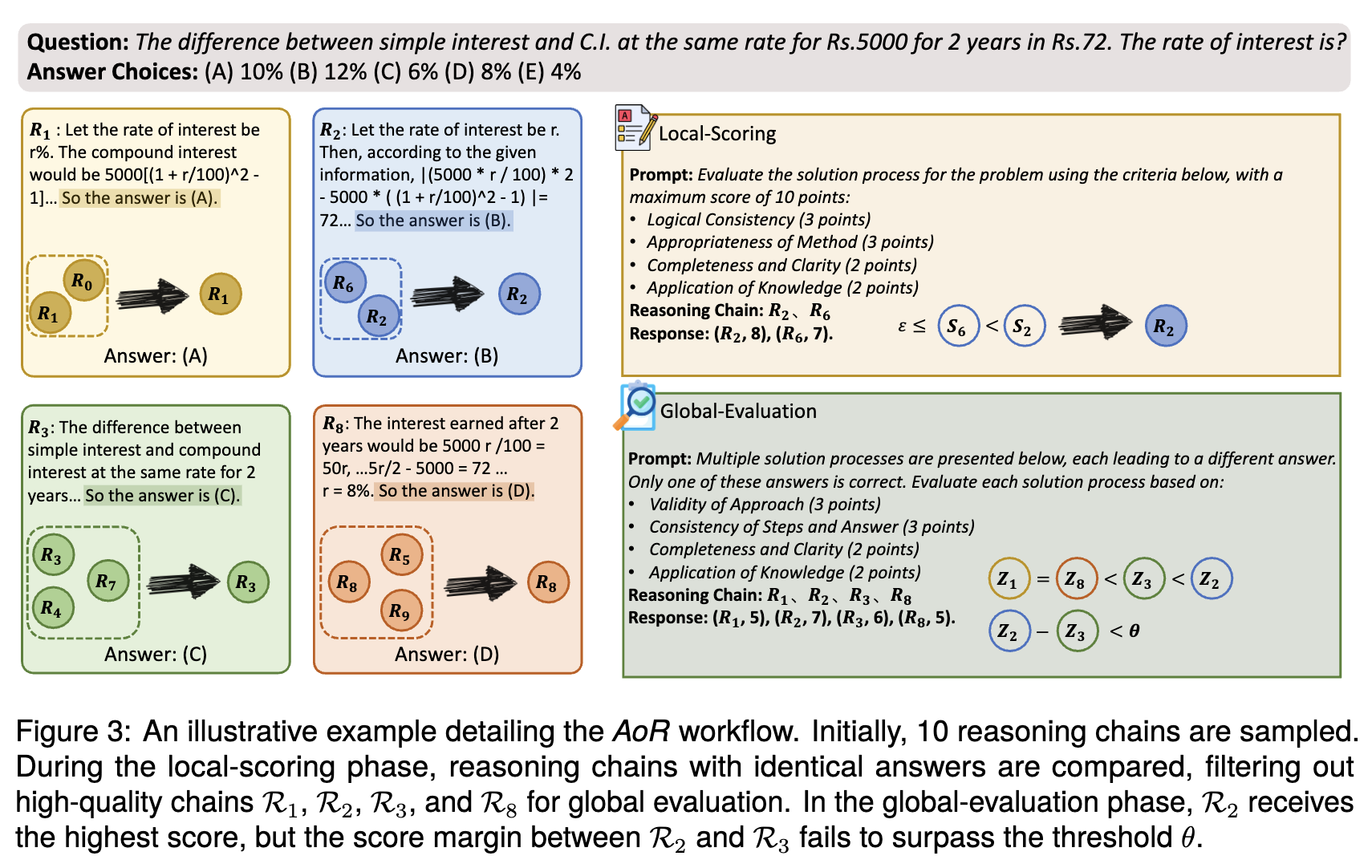
 1️⃣ CoT(Chain-of-Thought) 프롬프트를 사용하여 n번의 추론을 수행합니다. 동일한 답을 내놓은 추론을 같은 그룹으로 분류합니다.
1️⃣ CoT(Chain-of-Thought) 프롬프트를 사용하여 n번의 추론을 수행합니다. 동일한 답을 내놓은 추론을 같은 그룹으로 분류합니다.
🎨 그림에서는 10번의 추론을 수행하였습니다. 답 A를 내놓은 추론은 {R0, R1}, 답 B를 내놓은 추론은 {R2, R6}, 답 C를 내놓은 추론은 {R3, R4, R7}, 답 D를 내놓은 추론은 {R5, R8, R9} 입니다. 같은 대답을 내놓은 추론끼리 분류되어 있습니다.
2️⃣ Local-Scoring 단계에서는 같은 그룹으로 분류된 추론 체인을 평가합니다. 이 단계에서는 추론 과정의 타당성과 각 단계의 접근 방법을 평가하는 것이 목표입니다. 평가를 통해 점수가 산정되며, 상위 k개의 추론이 해당 그룹의 대표로 선발됩니다.
🎨 평가 방식과 점수가 작성된 프롬프트를 사용하여 각 그룹의 대표를 선발합니다. 답 A의 대표는 R1, B의 대표는 R2, C의 대표는 R3, D의 대표는 R8이 선택되었습니다.
 Local-Scoring 평가지표
문제를 해결하는 과정에서 다음 기준을 사용하여 최대 10점 만점으로 평가합니다:
Local-Scoring 평가지표
문제를 해결하는 과정에서 다음 기준을 사용하여 최대 10점 만점으로 평가합니다:
- 논리적 일관성 (Logical Consistency) - 3점: • 해결 과정이 논리적으로 일관성이 있는지 평가합니다.
- 방법의 적절성 (Appropriateness of Method) - 3점: • 사용된 방법이 문제 해결에 적절한지 평가합니다.
- 완전성과 명확성 (Completeness and Clarity) - 2점: • 해결 과정이 완전하고 명확한지 평가합니다.
- 지식의 적용 (Application of Knowledge) - 2점: • 문제 해결에 필요한 지식이 적절하게 적용되었는지 평가합니다.
3️⃣ Global-Evaluation 단계에서는 각 그룹에서 선택된 대표 추론을 평가합니다. 이 단계에서는 추론 과정과 결과 간의 일관성과 일치하는 정도를 가장 잘 보여주는 추론을 찾는 것이 목표입니다. k번의 평가 라운드 후, 평균 점수가 가장 높은 그룹을 최종 출력으로 선택합니다.
🎨 Local-Scoring과 유사한 형식의 프롬프트를 사용하되, 평가 방식은 약간 다릅니다. Local-Scoring을 통해 선발된 대표 추론을 모두 모아서 그 중 올바른 답변 하나를 선택하도록 합니다. 해당 답변이 최종 답변이 됩니다.
 Global-Evaluation 평가지표
아래의 여러 해결 과정 중 하나의 답이 맞다고 가정하고, 각 해결 과정을 다음 기준에 따라 평가합니다:
Global-Evaluation 평가지표
아래의 여러 해결 과정 중 하나의 답이 맞다고 가정하고, 각 해결 과정을 다음 기준에 따라 평가합니다:
- 접근의 타당성 (Validity of Approach) - 3점: • 접근 방식이 타당한지 평가합니다.
- 단계와 답변의 일관성 (Consistency of Steps and Answer) - 3점: • 각 단계와 최종 답변 간의 일관성이 있는지 평가합니다.
- 완전성과 명확성 (Completeness and Clarity) - 2점: • 해결 과정이 완전하고 명확한지 평가합니다.
- 지식의 적용 (Application of Knowledge) - 2점: • 문제 해결에 필요한 지식이 적절하게 적용되었는지 평가합니다.
📝 프롬프트 설명
Standard Prompting
Standard Prompting은 LLM(Large Language Model)이 질문 $Q$와 프롬프트 $T$를 입력으로 받아, 답변 $A$의 각 토큰을 순차적으로 생성합니다. 이때 각 단계에서의 가능성을 최대화하기 위해 답변을 생성합니다. 수식으로는 다음과 같이 표현됩니다:
\[P(A \mid T, Q) = \prod_{i=1}^{|A|} P_M(a_i \mid T, Q, a_{<i})\]여기서 $P(A \mid T, Q)$는 $T$와 $Q$를 입력으로 한 답변 $A$의 확률을 나타냅니다.
CoT Prompting
CoT(Chain of Thought) Prompting은 프롬프트 $T$를 개선하여 문제 해결 과정을 강화하고, 답변 $A$를 생성하기 전에 논리적 추론을 $R$로 통합하도록 LLM을 유도합니다. $R$과 $A$의 쌍을 reasoning chain이라 부릅니다. CoT 프롬프트의 확률은 다음과 같이 표현됩니다:
\[P(R, A \mid T, Q) = P(A \mid T, Q, R)P(R \mid T, Q)\]여기서 $P(R \mid T, Q)$와 $P(A \mid T, Q, R)$는 각각 다음과 같이 정의됩니다:
\[P(R \mid T, Q) = \prod_{i=1}^{|R|} P_M(r_i \mid T, Q, r_{<i})\] \[P(A \mid T, Q, R) = \prod_{j=1}^{|A|} P_M(a_j \mid T, Q, R, a_{<j})\]Self-Consistency
Self-Consistency는 CoT를 사용하여 n개의 추론 체인을 샘플링합니다. 각 추론 체인은 답변$A$와 함께 여러 개의 reasoning chains $(R_i, A_i)$로 구성됩니다. Self-Consistency는 각 추론 체인에서 가장 빈번하게 등장하는 답을 최종 답으로 선택합니다. 이 접근 방식은 다음과 같이 표현됩니다:
\[A^* = \arg \max_a [(\{(R_i, A_i)\mid A_i = a\}]\]이는 가장 자주 등장하는 답변이 최종 답변으로 선택됨을 의미합니다.
📈 평가
수학적 추론, 상식 추론, 기호적 추론의 세 가지 유형의 작업에 대한 실험 결과, AoR은 CoT(Chain of Thoughts) 프롬프트, Complexity-Based 프롬프트, Self-Consistency 등 여러 기존 방법보다 우수한 성능을 보였습니다.
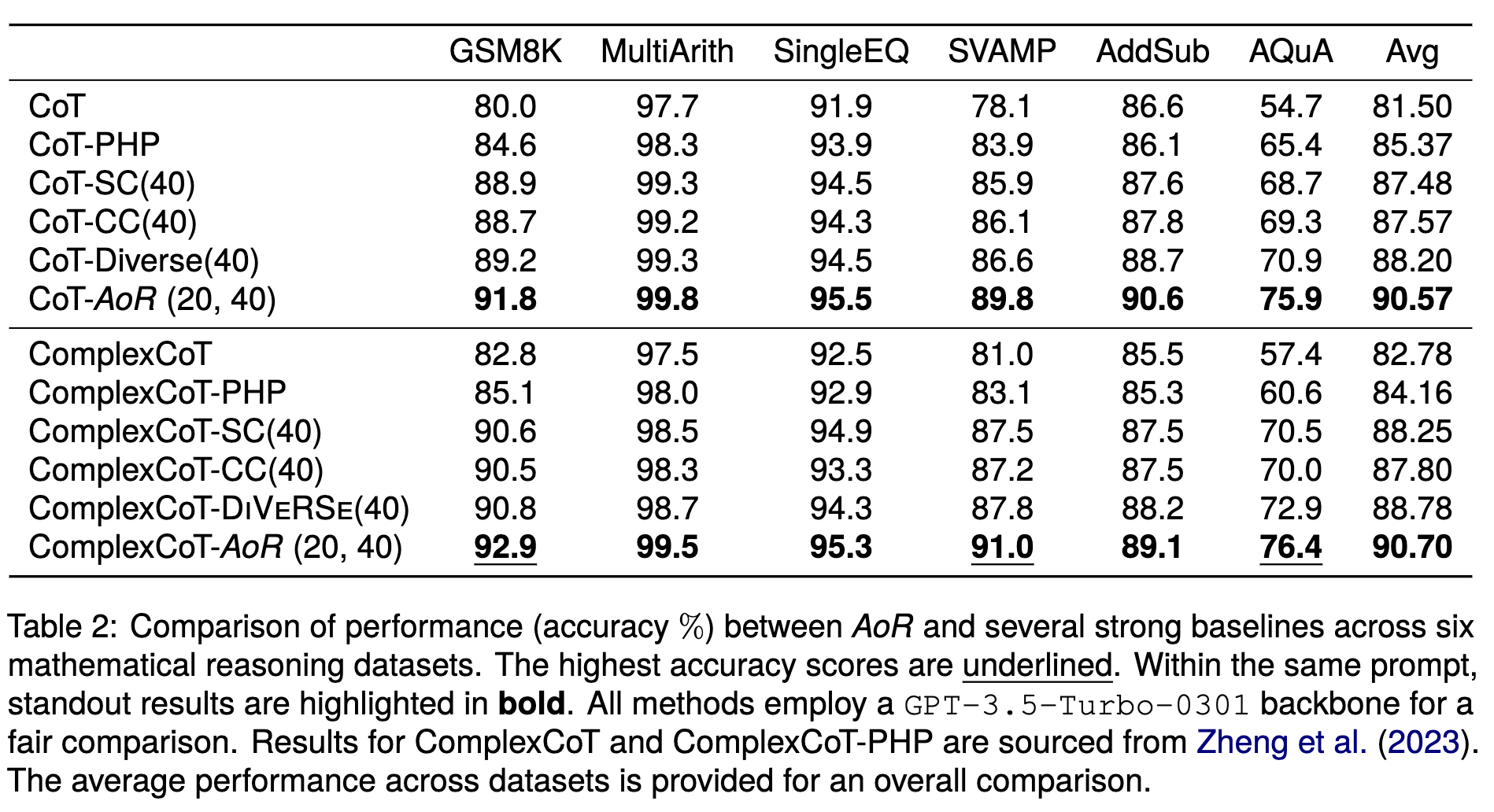 모든 방식에 GPT-3.5가 사용되었기 때문에, 파라미터 수가 적은 모델에서도 성능 향상이 나타날지는 추가 실험을 통해 확인해야 합니다.
모든 방식에 GPT-3.5가 사용되었기 때문에, 파라미터 수가 적은 모델에서도 성능 향상이 나타날지는 추가 실험을 통해 확인해야 합니다.
🔬 실험
- Self-Consistency: 40번의 추론을 수행함
- 주 실험에서는 GPT-3.5-Turbo-0301 사용.
- 토론 부분에서는 GPT-4-0314, Claude-2, LLaMA-2-70B-Chat, Mixtral-8x7B 등 다양한 모델 사용
- GPT-3.5-Turbo, GPT-4, Claude-2: temperature 1
- LLaMA: 공식 권장에 따라 temperature 0.6
- Mistral: 최적 성능을 위해 temperature 0.7
- 기본적으로 20개의 추론 체인 샘플링
- 대표 추론 체인 수 $k = 3$.
- 스코어링 임계값 $ϵ = 6$.
- 종료 기준 임계값 $θ = 2$
- 각 반복마다 추가로 5개의 추론 체인 샘플링